8 Key Insights into Kubernetes v1.36's PSI Metrics Graduation to GA
Since its introduction in the Linux kernel back in 2018, Pressure Stall Information (PSI) has given system administrators a much clearer picture of resource saturation before it snowballs into a full-blown outage. With the release of Kubernetes v1.36, PSI metrics have officially graduated to General Availability (GA), providing a stable and reliable interface for observing resource contention at the node, pod, and container levels. In this article, we break down the eight most important things you need to know about this milestone—from what PSI is and why it matters, to the rigorous performance testing that proved it's ready for production.
1. What Is Pressure Stall Information (PSI)?
At its core, PSI is a kernel-level mechanism that measures how long tasks are stalled waiting for a resource—be it CPU, memory, or I/O. Unlike traditional metrics that simply report utilization percentages, PSI captures the real cost of contention: the time tasks spend queued or blocked. It packages this data into easy-to-read percentages across three resource types, giving operators a high-fidelity signal that reveals hidden bottlenecks. For example, even when a node’s CPU utilization is below 100%, PSI can show that scheduling delays are causing severe latency for certain workloads. This makes PSI an indispensable tool for proactive capacity management and troubleshooting.
2. Why PSI Beats Traditional Utilization Metrics
Relying solely on CPU or memory usage can be dangerously misleading. A node might report 80% CPU utilization while tasks are experiencing significant stalling due to kernel scheduling or I/O waits. PSI fills the gap by directly measuring the time tasks spend in a stalled state. This means you see the actual impact of resource contention, not just a smoothed-over utilization number. For Kubernetes operators, this is a game-changer: you can now distinguish between a healthy node that’s simply busy and one that’s silently throttling your applications. PSI provides the early warning system needed to prevent performance degradation from escalating into outages.
3. The Two Key Data Points PSI Provides
PSI exposes two types of data that together give a complete picture of resource pressure:
- Cumulative Totals: The absolute time spent in a stalled state since boot. This is useful for calculating total downtime or correlating with application slowdowns over long periods.
- Moving Averages: Time-averaged values over 10-second, 60-second, and 300-second windows. These averages allow operators to distinguish between transient spikes (e.g., a brief burst of writes) and sustained resource tension (e.g., a memory leak that gradually starves the node). The combination of cumulative and averaged data gives both retrospective and near-real-time visibility.
4. How Kubernetes v1.36 Integrates PSI at Node, Pod, and Container Levels
With the GA graduation in v1.36, PSI metrics are now exposed through the Kubernetes API at three granularities: node-wide, pod-level, and container-level. This means you can drill down from a noisy neighbor on a node to a specific container that’s causing memory pressure. The metrics are collected by the kubelet from cgroup v2 interfaces and served via the /metrics endpoint, making them easily consumable by Prometheus and other monitoring tools. This integration enables operators to set fine-grained alerts, such as triggering a pod eviction when a container’s PSI memory moving average exceeds a threshold for more than 60 seconds.
5. Performance Testing: Proving PSI's Production Readiness
One of the biggest concerns when graduating a telemetry feature to GA is the overhead it introduces. To address this, SIG Node conducted extensive performance validation on high-density workloads (80+ pods) across various machine types. The testing focused on two scenarios to isolate the impact of the kubelet and kernel-level collection respectively:
- Kernel PSI ON / Kubelet Feature OFF vs Kernel PSI ON / Kubelet Feature ON (measures kubelet overhead)
- Kernel PSI OFF / Kubelet Feature ON vs Kernel PSI ON / Kubelet Feature ON (measures kernel overhead)
These controlled experiments allowed the team to quantify exactly how much extra resource consumption the PSI feature adds in real-world conditions.
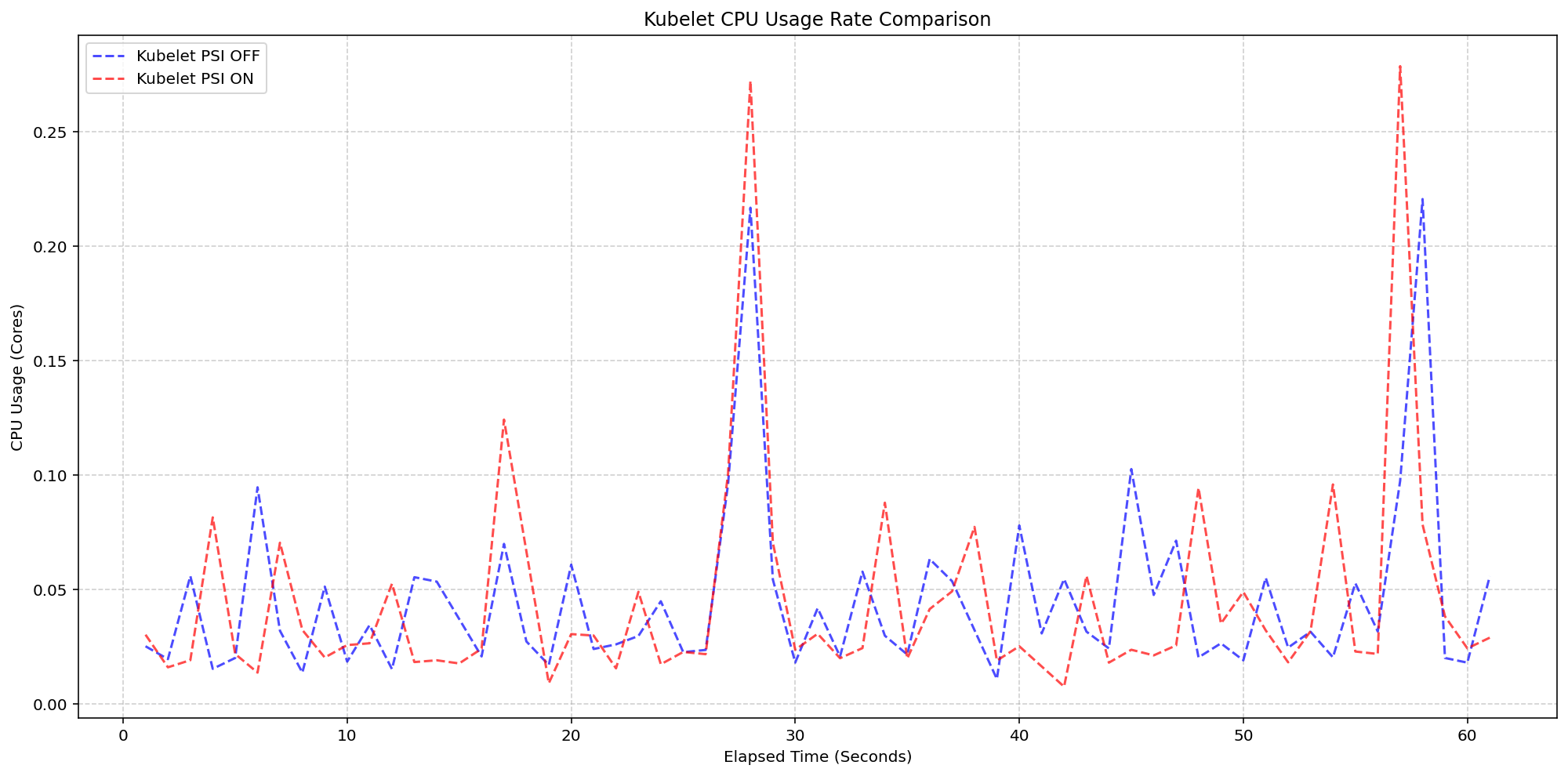
6. Scenario 1: Kubelet Overhead — Minimal Impact
In the first scenario, the team ran the same workloads on 4-core machines, with the Linux kernel already tracking PSI by default (psi=1). They toggled the KubeletPSI feature gate to compare CPU usage when the kubelet actively queries and exposes these metrics versus when it does not. The results were striking: the synchronized bursts in CPU usage were nearly identical in both magnitude and frequency. This confirmed that the kubelet’s collection logic is extremely lightweight, blending seamlessly into standard housekeeping cycles. The additional CPU consumption stayed within 0.1 cores (2.5% of total node capacity), meaning there is no practical impact on production workloads. The feature is safe to enable even on resource-constrained nodes.
7. Scenario 2: Kernel Overhead — Slight but Negligible
The second scenario evaluated system-level overhead by comparing a setup where the kernel tracked PSI with one where it did not. The system CPU usage lines for the Kubelet PSI–enabled cluster followed the same pattern as the disabled cluster, with only a slight expected increase from the baseline. Once the OS is already tracking PSI (which is common in modern Linux distributions), the act of Kubernetes reading those cgroup metrics adds negligible overhead. Even on high-density nodes with 80+ pods, the total system CPU increase was minimal—well within normal operating variance. This validates that PSI metrics can be collected without degrading the performance of other workloads or the kubelet itself.
8. Real-World Implications for Cluster Operators
With PSI metrics now GA in Kubernetes v1.36, cluster operators gain a powerful new tool for capacity planning, anomaly detection, and root cause analysis. Instead of relying on indirect signals like pod restarts or application latency spikes, you can now directly observe when a node’s CPU, memory, or I/O is causing tasks to stall. This enables proactive actions such as rescheduling pods, increasing resource limits, or scaling the cluster before performance degrades. Moreover, because the overhead is negligible, there’s no reason not to enable this feature—it provides high-value data at virtually no cost. For any team running production Kubernetes, upgrading to v1.36 and turning on PSI metrics is a no-brainer.
The graduation of Pressure Stall Information to GA in Kubernetes v1.36 marks a significant step forward in observability for container orchestration. By providing accurate, low-overhead measurements of resource contention at multiple levels, PSI empowers operators to make smarter, faster decisions. Whether you're troubleshooting a noisy neighbor or planning capacity for a new deployment, PSI gives you the insights you need—without the performance penalty.
Related Articles
- Linux Kernel Drops Zero-Copy Support in AF_ALG Crypto Interface Amid Heightened Security Fears
- How to Install or Upgrade to Fedora Asahi Remix 44 on Apple Silicon Macs
- How to Navigate a Prolonged DDoS Attack on Your Web Infrastructure: A Case Study from Canonical
- DAMON Subsystem Gets Major Overhaul: Tiering, THP Monitoring, and More Unveiled at 2026 Linux Summit
- HugeTLB Memory Preservation Priority for Linux Live Updates at 2026 Summit
- Canonical and Ubuntu Hit by Prolonged DDoS Attack Following Vulnerability Disclosure
- Critical Bug in Linux Congestion Control Could Stall QUIC Connections, Cloudflare Finds
- Ubuntu DDoS Attack: Key Questions and Answers